
How to Make LLMs Deterministic
LLM Parameters Testers Should Actually Understand: Temperature, Top-K, Top-P, and frequency penalties.

Most testers want the same thing from Large Language Models:
predictability, consistency, and repeatability.
But LLMs aren’t deterministic by default. They’re probabilistic systems designed to produce varied answers. Even small defaults—like OpenAI’s temperature—introduce randomness that makes output shift from run to run.
To take control, testers need to understand the four parameters that matter:
temperature, top-k, top-p, and frequency penalty.
These determine how “creative” or “stable” the model behaves.
Below is a clear, tester-friendly guide to each parameter—and the exact settings that make an LLM as deterministic as possible.
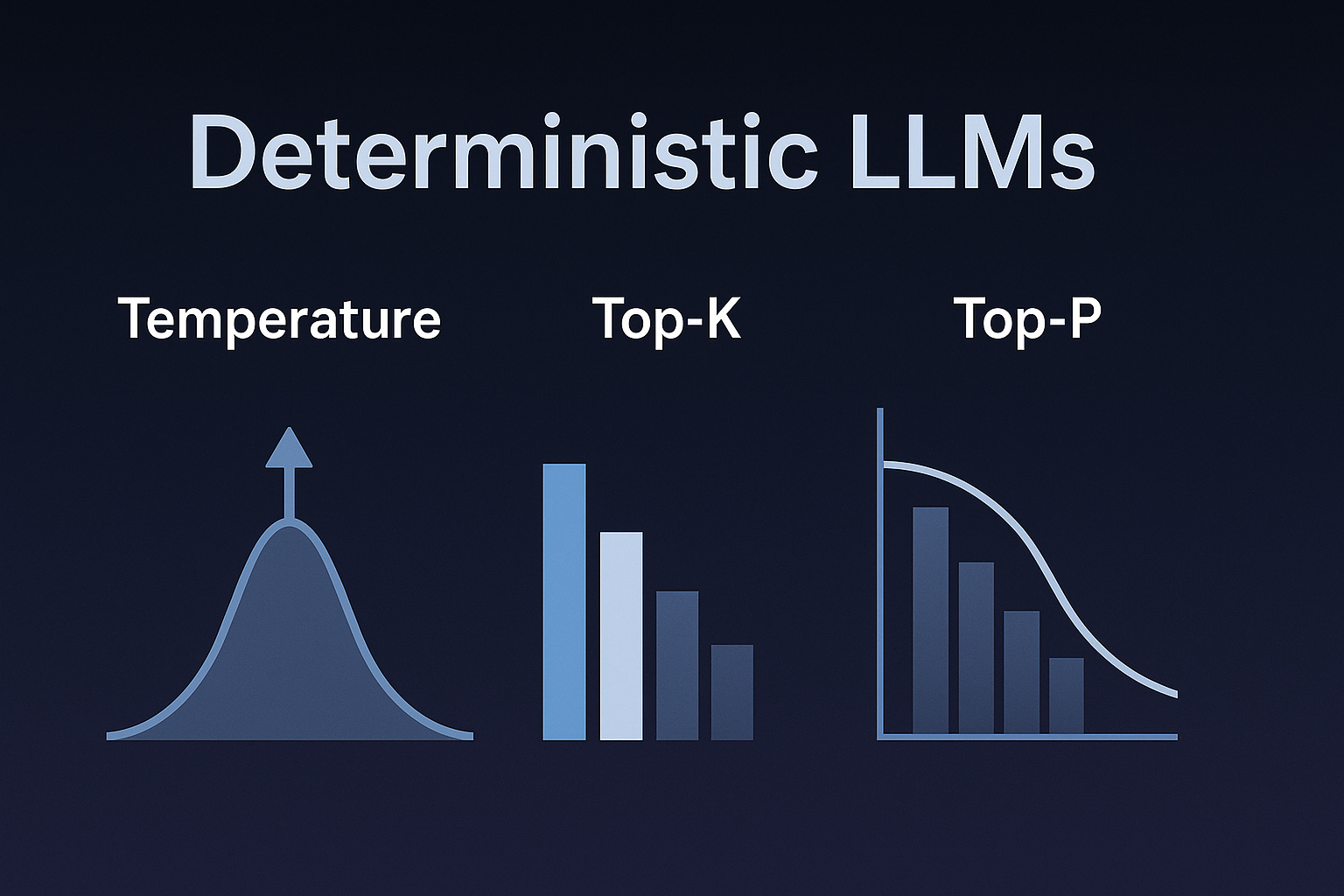
Temperature
Temperature controls randomness.
A low temperature means the model strongly prefers highly probable tokens; a high temperature allows the model to take more risks.
Low temperature (0.0–0.2) → deterministic, factual, consistent
High temperature (0.7–1.2) → creative, surprising, more variable output
Tester takeaway
For consistent test results:
Set temperature to 0.0.
This alone removes most randomness from the model.
Top-k
Top-k limits how many tokens the model is allowed to consider.
If top-k = 5, only the 5 highest-probability tokens are eligible.
If top-k = 1, the model must choose the single most likely next token.
Lower top-k → more repeatable
Higher top-k (or “none”) → more variety and drift
Tester takeaway
For strict determinism:
Set top-k = 1.
This forces greedy decoding—choosing the same next token every time.
Top-p (Nucleus Sampling)
Top-p sets a probability cutoff instead of a count.
The model includes the smallest set of tokens whose cumulative probability reaches p.
Example:
If the top three tokens add up to 0.92 probability, and top-p = 0.9, only those three tokens are considered.
Low top-p (0.1–0.3) → very narrow: near-deterministic
High top-p (0.9–1.0) → more variety
Tester takeaway
If you already set top-k = 1, then top-p doesn’t matter.
But a safe deterministic setting is:
top-p = 1.0.
Frequency Penalty
Frequency penalty discourages the model from repeating the same tokens.
Each time a token appears, the model penalizes it slightly on subsequent uses.
This parameter affects the model’s wording rather than its topic.
Low (0.0) → no penalty, stable phrasing
Moderate (0.2–0.5) → more paraphrasing
High (1.0+) → strong avoidance of repetition
Tester takeaway
To maximize consistency of phrasing:
Set frequency penalty = 0.0.
This stops the model from trying to “avoid repeating itself,” which introduces unnecessary variation.
Presence Penalty
(Optional, but often paired with frequency penalty)
Presence penalty pushes the model to introduce new ideas.
It penalizes tokens that have already appeared, but applies pressure at the concept level rather than the frequency level.
Low (0.0) → stays on topic, predictable
High (0.5–1.0+) → more tangents, more novelty
Tester takeaway
For repeatable results:
Set presence penalty = 0.0.
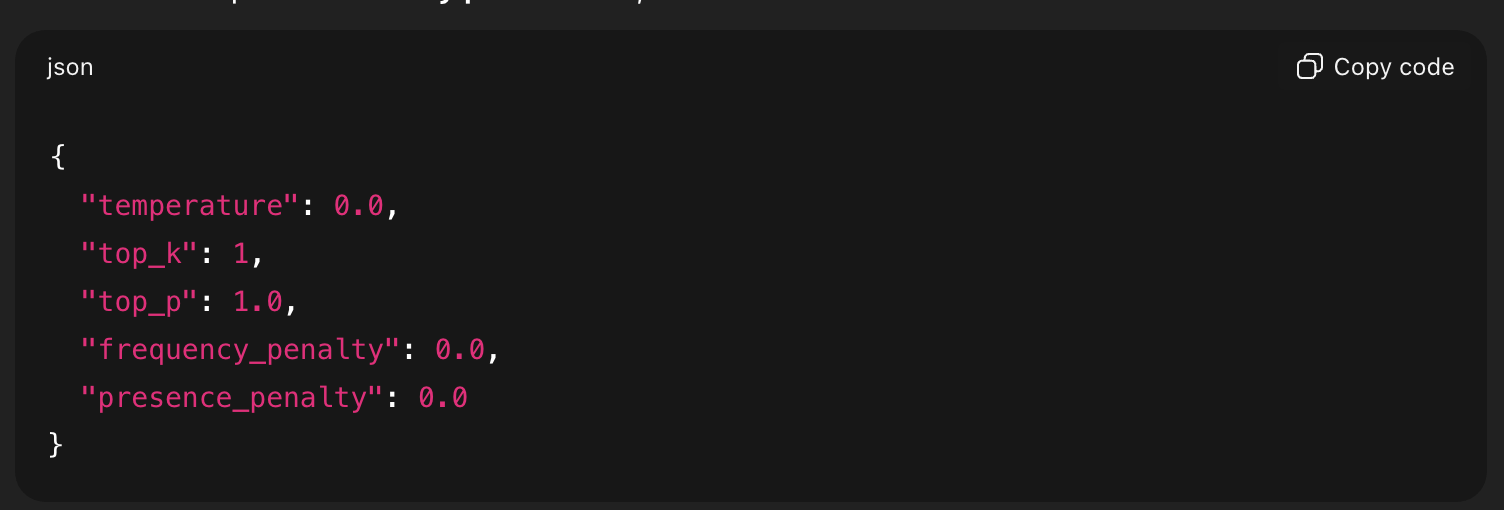
The Most Deterministic Settings Possible
To make an LLM behave as consistently as it can, use this configuration:
{
“temperature”: 0.0,
“top_k”: 1,
“top_p”: 1.0,
“frequency_penalty”: 0.0,
“presence_penalty”: 0.0
}
This combines greedy decoding with no stylistic or topic-shifting penalties.
It is the closest an LLM gets to stable, repeatable, testable output.
A More Practical “Strongly Consistent” Setting
If greedy output becomes too brittle or terse, use:
{
“temperature”: 0.1,
“top_k”: 10,
“top_p”: 0.9,
“frequency_penalty”: 0.0,
“presence_penalty”: 0.0
}
This is still highly predictable but avoids some of the edge cases of pure greedy decoding.
How to Use These Values in LLMs
Unfortunately you can’t adjust these values on the normal ChatGPT page. You can adjust many of these paramaters in the ‘playground’ version of ChatGPT though, e.g. for OpenAI it is
https://platform.openai.com/chat/edit?models=gpt-4.1
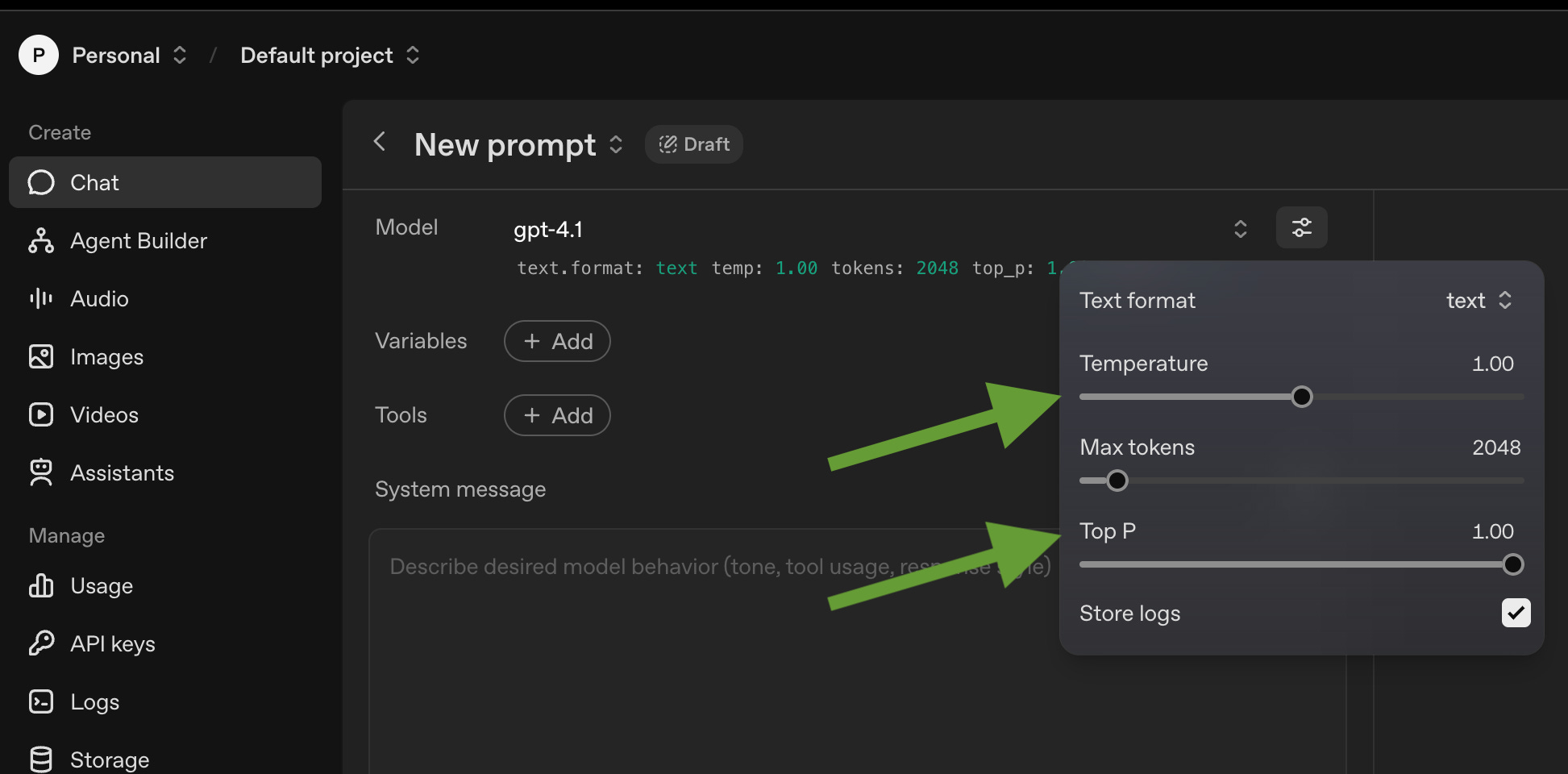
You can also pass values for temperature and Top-P and Top-K as paramaters to API calls.
A good video for folks that like that sort of visual learning:
Together, these parameters can tame an LLM into acting more like a deterministic system—exactly what testers need when verifying quality, reproducibility, and regression behavior.
--Jason Arbon, CEO testers.ai